
27 Oct Deep Web

¿Cuándo hablamos de Deep Web? Se pueden definir dos casos:
-
Webs que no se puede encontrar en los buscadores habituales como Google, Bing, Yahoo… es decir, páginas de internet con poca o nula visibilidad.
-
Webs que necesitan otra tecnología para acceder a ellas porque pertenecen a otras redes que mencionaremos más adelante.

El segundo caso se debe a que existen otras redes que no son Internet que también son públicas, pero necesitas un software específico para acceder a ellas ya que los navegadores habituales como Internet Explorer, Firefox, Chrome, etc. no están adaptados a dichas redes, simplemente no funcionan. Las redes más conocidas son TOR, I2P y Freenet. Cuando hablamos de Deep Web en muchas ocasiones se ignora a las webs invisibles como parte de esta, es decir, el primer caso, y se define como Deep Web a las redes públicas que no son Internet. Es decir, cuando busquéis información sobre qué es la Deep Web, os vais a encontrar varias definiciones. Algunos engloban las redes como TOR, I2P y Freenet como parte de Internet, como por ejemplo el que hizo la primera imagen de este post. Otros toman la Deep Web como solo las redes que no son Internet. Otros la definen por aquella que contiene contenido ilegal del tipo pedófilo, virus, estafas, asesinatos, contratación de sicarios… Yo prefiero definirla como el conjunto de webs, foros y recursos que aunque públicos, no son fácilmente accesibles y son prácticamente desconocidos por la sociedad que está habituada al uso de Internet, es decir, personas que usan todo el día Internet y que no serían capaces de encontrar el contenido alojado en dichos recursos. También se englobaría las webs que no tienen contenido visible y que este sólo aparece tras llamadas específicas a la base de datos.
Debido al anonimato, a que las conexiones estén cifradas y los buscadores especializados en estas redes tienen muy poco contenido indexado, la ciberdelincuencia ronda por esta red. Aunque no tenemos que olvidar que la ciberdelincuencia también ronda por las webs que visitamos, habitualmente nos encontramos con estafas de todo tipo. Es muy fácil ocultar cosas y que sólo aquellos que uno quiera puedan acceder al recurso. Por ello mismo está vigilada por las agencias de seguridad de la mayoría de los países. En el caso español tenemos el ejemplo de BIT (Brigada de Investigación Tecnológica) de la Policía Nacional. BIT lucha, entre otras muchas cosas, para evitar la existencia de redes de pedófilia y que puedan compartir su contenido, venta de drogas y estafas.
No te arrestarán si navegas por la Deep Web, pero probablemente te empezarán a vigilar si empiezas a navegar por contenidos poco «recomendables». Y algunos hackers te intentarán hackear si no andas con cuidado y empiezas a ejecutar cosas que no debes ya que muchos protocolos de alto nivel envían información personal e ir publicando tu información en una red llena de hackers y policía no es muy inteligente.


Cada nodo genera una comunicación segura con el siguiente encapsulando el mensaje bajo una nueva encriptación, el mensaje tendrá “capas” como las cebollas.
Una forma de navegar por dominios .onion sin ejecutar TOR es con el uso de Calyphroxy que te permite navegar bajo la protección de un proxy. Por cierto, si no tienes claro qué es un proxy, una explicación sencilla es la siguiente, tú eres A y quieres hacer una petición a C, si usas un proxy B, la petición será de A a B y de B a C ocultando de esta forma que A ha realizado la petición a C. El proxy B almacenará el número de tu petición, cuando reciba la respuesta te buscará en su tabla y te enviará la información. Cualquiera que rastree tráfico sólo verá que hay comunicaciones de A al proxy B y del proxy B a C, y nunca de A a C. Para saber que A mantiene comunicación con C, deberá entrar en el proxy (algo que no es fácil) y revisar las tablas, que por norma general, están codificadas. Si te ocultas bajo varios proxy, la tarea de encontrarte será sumamente tediosa y casi imposible, quedando tu identidad en el más absoluto anonimato. Los proxy se pueden concatenar (un proxy conectado a otro) lo que añadiría más anonimato.
Hay un motor de búsqueda que ha indexado una pequeña parte de los dominios .onion. Este buscador está haciendo competencia a Google y, algo maravilloso, no te rastrea ni obtiene resultados respecto a lo que ya has buscado anteriormente, como hace Google. ¿Por qué creeis que los anuncios de Google tienen relación con lo que has buscado días antes? También Gmail busca “palabras clave” en tu correo para hacer una publicidad personal, y sí, eso significa que leen tu correo. Este motor de búsqueda se conoce como DuckDuckGo y se puede usar bajo TOR en la siguiente url 3g2upl4pq6kufc4m.onion.
La red de comunicaciones TOR permite, entre otras cosas, lo siguiente:
-
Anonimato.
-
Esto es algo a lo que no estamos acostumbrados en la actualidad en la que ya no sólo publicamos nuestro nombre completo, sino nuestra dirección, teléfono, correo electrónico, ciudad en la que vivimos, gustos, experiencias… Un perfil abierto es un manjar para aquellos que suplantan identidades.
-
-
Webs dinámicas.
-
Si publicas contenido, será difícil que lo encuentren y lo visiten.
Un ejemplo, eres un terrorista, desarrollas una web simple con un contenido diferente a cosas terroristas (sobre el poder de los extraterrestres en la política mundial, como hacer galletas, etc.), das la posibilidad de entrar a más contenido introduciendo un usuario y una contraseña (subimos el nivel de seguridad), introduces más contenido del mismo tipo para evitar sospechas. Una vez que estás en esta sección, tienes la posibilidad de ejecutar una solicitud de información a la base de datos generando una web dinámica. Un salto más es mostrar el contenido codificado que sólo aquellos que tengan el programa y contraseña específica podrán decodificar. Así solamente algunos podrán ver las cosas terroristas que publicas.
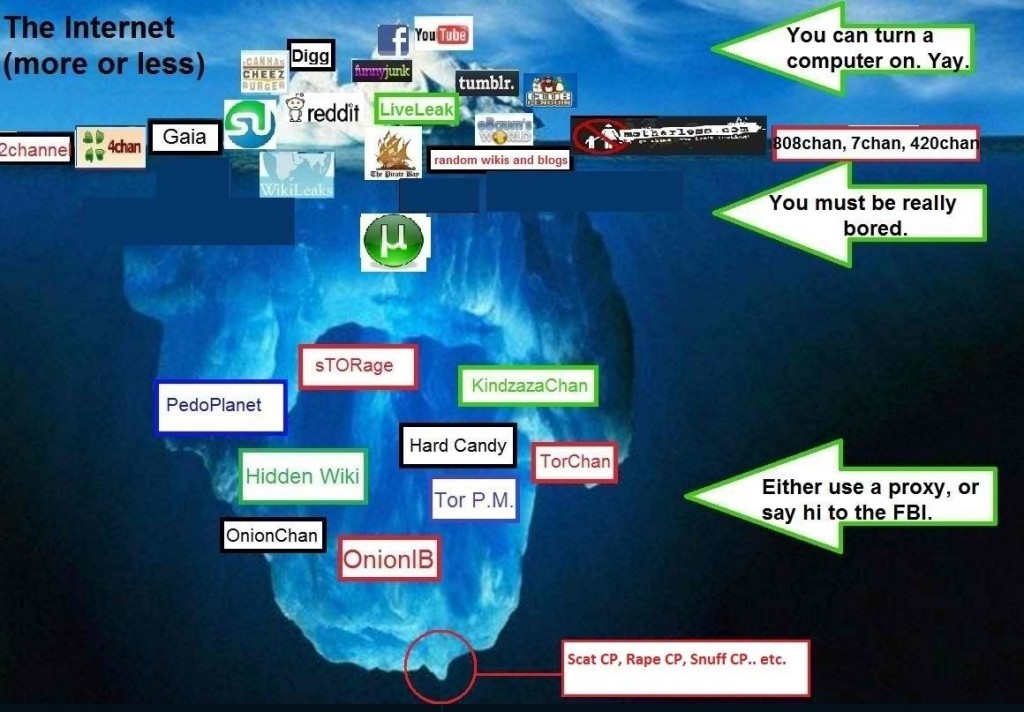
Aunque no es del todo correcto, se han llegado a definir una serie de niveles para explicar de forma simple cómo está dispuesto el contenido en la suma de redes, como si Internet y las redes de TOR, I2P y Freenet formasen un conjunto. Algunos definen más o menos niveles pero no hay nada «oficial» ni claro, esto es sólo para haceros una idea.
-
El nivel 1 o Surface Web: webs como Hablando de Ciencia, Naukas, Google, Facebook, Twitter…
-
El nivel 2 o Bergie Web: páginas con un acceso un poco más complicado y menos indexadas por los buscadores, aquí nos encontramos con 4Chan, servidores FTP, algunos foros y mucho porno. Estos serían los recursos que están entre la Surface Web y las páginas invisibles.
Los siguientes niveles corresponden con lo denominado como Deep Web, aunque el nivel 3 es el que tenga el nombre.
-
El nivel 3 o Deep Web: aquí encontramos con el resto las páginas invisibles y parte del contenido de las redes TOR, I2P y Freenet. Aquí empezamos a atisbar lo peor del ser humano (zoofilia, pedofilia, drogas, sicarios, venta de órganos, trata de personas…) aunque también podemos encontrar documentos de diferentes gobiernos (tanto reales como falsos) y vídeos conspiranóicos (aunque muchos de estos los puedes encontrar en Youtube). También hay bastante información sobre hacking y creación de virus.
-
El nivel 4 o Charter Web: esto sería correspondiente a lo que queda de las redes TOR, I2P y Freenet, aquí muchos hackers, virus, ciberpolicía y contenido más grotesco que en el nivel anterior.
-
El nivel 5 o Marianas Web: es un mito. Las leyendas urbanas sobre este sitio son que todo el contenido está cifrado, que sólo puedes entrar por invitación, que pertenece a algún Gobierno, que su contenido incita al suicidio y a saber qué más incoherencias.
Tenéis que ser conscientes que la privacidad y la seguridad informática que tenemos al navegar por la Internet que todos conocemos es bastante escasa, descargamos software de todo tipo, dejamos puertos abiertos, damos nuestra información de contacto y personal, no cambiamos las contraseñas y utilizamos contraseñas que tienen que ver con nuestra personalidad entre otros fallos que cometemos al exponer nuestra privacidad y acceso a nuestro ordenador. La Deep Web es bastante insegura porque hay muchos hackers rondando por ella, por eso tenéis que ser sumamente precavidos. Hay que tener en cuenta que TOR es bastante seguro, pero no es infalible. Lo mismo pasa con el uso de proxys. Algunos consejos para navegar por la Deep Web son:
-
Usad un servicio que os de anonimato y cifre vuestro tráfico.
-
Usad los servicios detrás de un proxy como mínimo.
-
No descarguéis contenido de ningún tipo.
-
No deis ningún tipo de información personal y, si es posible, pasad sin dejar huella, así que nada de comentarios en ninguna web.
-
No os metáis en Facebook ni nada por el estilo, no ejecutéis Javascripts, ni cookies, ni nada.
-
Usad un antivirus ponente y un buen firewall.
-
Si una web no os da buena espina, marcharos.
Alexis Ramos Amo (colaborador externo)
Referencias:
The Deep Web: Surfacing Hidden Value
Deep Web: en las profundidades de Internet
Brigada de Investigación tecnológica
Internautas21: mi experiencia entrando en la Deep Web
Las profundidades de Internet: LA DEEP WEB
Análisis de Deep Web por Last Dragon
ununcuadio
Publicado el 13:19h, 27 octubre¡Qué curioso! Mi ignorancia informática no me hacía sospechar nada de esto 😛 muy interesante y bien explicado, pero Víctor, ten cuidado, no te vayan a fichar por enaltecer el terrorismo o algo así xD
Víctor Pascual del Olmo
Publicado el 11:03h, 29 octubreDolores, vuelve a leer el artículo que el que publiqué era la primera versión, menos mal que tenía una copia en doc 🙂
ununcuadio
Publicado el 16:54h, 29 octubreLeído, cocina 🙂 interesante también lo que comenta Iñaki 😛
Iñaki
Publicado el 22:04h, 27 octubreHay unas cuantas cosas que aclarar aquí. Voy por puntos.
1) Se confunde, una vez más, Internet y web. La web solo es una parte de Internet, y aquí se habla de web: hipertexto servido a través de HTTP. Centrémonos en esto.
2) «Deep web» se ha definido tradicionalmente (como dices al principio bien, aunque lo del porcentaje es inventado porque nadie lo sabe) como todo aquel contenido web no indexado por buscadores. ¿Es «otro tipo de red», «navegación diferente», etc.? No.
3) ¿La deep web aparece por la «imposibilidad técnica de indexar todo el contenido de [la web] al mismo ritmo del que se crea? Rotundamente no. Aparece porque los crawlers de los buscadores siguen links. Si hay contenidos a los que no se puede llegar a través de links, no se indexan. Así de fácil. Ejemplo: una web que presenta una interfaz con un buscador que manda peticiones contra una base de datos. No hay links. Hasta que no haces una búsqueda, la web no devuelve contenidos, así que estos no son indexables. Esa base de datos puede ser, por ejemplo, de datos públicos de agencias gubernamentales. Precisamente hay estudios que muestran que una grandísima parte de la deep web se trata de este tipo de datos accesibles a través de formularios. Por tanto, estos contenidos no tienen nada de ilegal, ni raro, ni «aparecen y desaparecen».
4) A esto se añade la aparición de los Hidden Services de Tor. Tor permite la navegación anónima, esto es, ocultar la IP del cliente. Los Hidden Services permiten, además, ocultar la IP del servidor. Por tanto, cualquiera puede poner un servidor web en el ordenador de su casa y ponerlo en Internet de forma anónima a través de Tor (de ahí las URL .onion, que son identificadores para establecer la conexión). Así, Tor actúa como una capa P2P de privacidad.
5) No hay más historia en el funcionamiento de Tor. No hay nada oscuro en ello y, desde luego, nada de «niveles» ni historias. Esto salió de la mente perturbada de algún usuario de 4chan.
6) Evidentemente, el anonimato que proporcionan los Hidden Services de Tor hace que brote la mierda. Pero también hay mucha mierda en la web indexada, no lo olvidemos. ¿Hackers, virus agazapados en la deep web para jodernos? Pues claro que los habrá, pero no creo que más que en la web indexada. Más bien al revés. El argumento es sencillo: muy poca gente navega con Tor. Es más rentable la web indexada, lo mismo que es más rentable hacer virus para Windows.
Y creo que eso es todo. Espero que sirva.
Víctor Pascual del Olmo
Publicado el 11:02h, 29 octubreIñaki, la versión que leíste fue la primera de todas, tuve un problema con el wordpress y no se publicó la completa. Espero que la disfrutes y siento las molestias.
Bitacoras.com
Publicado el 01:07h, 28 octubreInformación Bitacoras.com
Valora en Bitacoras.com: ¿Crees que podéis acceder fácilmente a todo el contenido de Intenet? ¿Qué pensaréis si os digo que usando motores de búsqueda (Google, Bing, Ask, Yahoo…) sólo podéis acceder a aproximadamente al 4% de todo el contenido? A tod..…
Jesús
Publicado el 10:11h, 28 octubreCon perdón, pero creo que has visto muchas películas. Sí, si usas Tor encuentras gente que vende drogas, sicarios y demás, pero en el 99% de los casos son simples estafas corrientes y molientes. Y todos esos niveles profundísimos con cosas súper-secretas y conspirativas son bulos como pianos. No hace falta complicarse tanto la vida para hacer cosas ilegales.
De hecho, en el enlace que das como referencia comentan que, en alguno de esos niveles, se encuentra la ubicación de la Atlántida. Nivelazo de referencia…
Víctor Pascual del Olmo
Publicado el 10:34h, 28 octubreBuenas,
He estado buscando información en varias webs, he filtrado la máxima porquería posible y he consultado este tema con varias personas, yo mismo menciono que sea un mito el último nivel.
Los niveles son relativos y son más una metáfora que otra cosa para dar a entender que siempre hay contenido menos accesible, esto mismo está mencionado en el artículo.
Víctor Pascual del Olmo
Publicado el 11:02h, 29 octubreJesús, la versión que leíste fue la primera de todas, tuve un problema con el wordpress y no se publicó la completa. Espero que la disfrutes y siento las molestias.
Pingback:Internet profunda | Hablando de Ciencia | Art&i...
Publicado el 19:16h, 28 octubre[…] Análisis de la Deep Web y de su contenido. […]
Lucida Vargas
Publicado el 19:40h, 13 mayoVictor nos desarrolla este interesante tema, no obstante, también aprendí en https://zarza.com/internet-profunda-deep-web/ que hay un gran mercado para los informaticos, donde las empresas pagan por que sus contenidos sean monitoreados, y así darse por enterados primero, en el caso de que ronden sus bases de datos.
Casos como estos se han dado con Google, Facebook, y otras grandes firmas. Quizá valdría el apunte en tan importante tema.